Angel Lopez
AI Engineer (GenAI-focused) with a Data Engineering background. Built production agentic systems with tool/function-calling and RAG (OpenAI/Gemini embeddings, Postgres/pgvector, Chroma) shipped as APIs with Python, Django, Docker, and Pydantic. Delivered automation reducing operational workload by up to 60% and supported monetization via usage analytics and pricing redesign. AWS (EC2, S3, IAM). English B2.
Experience
AI Developer
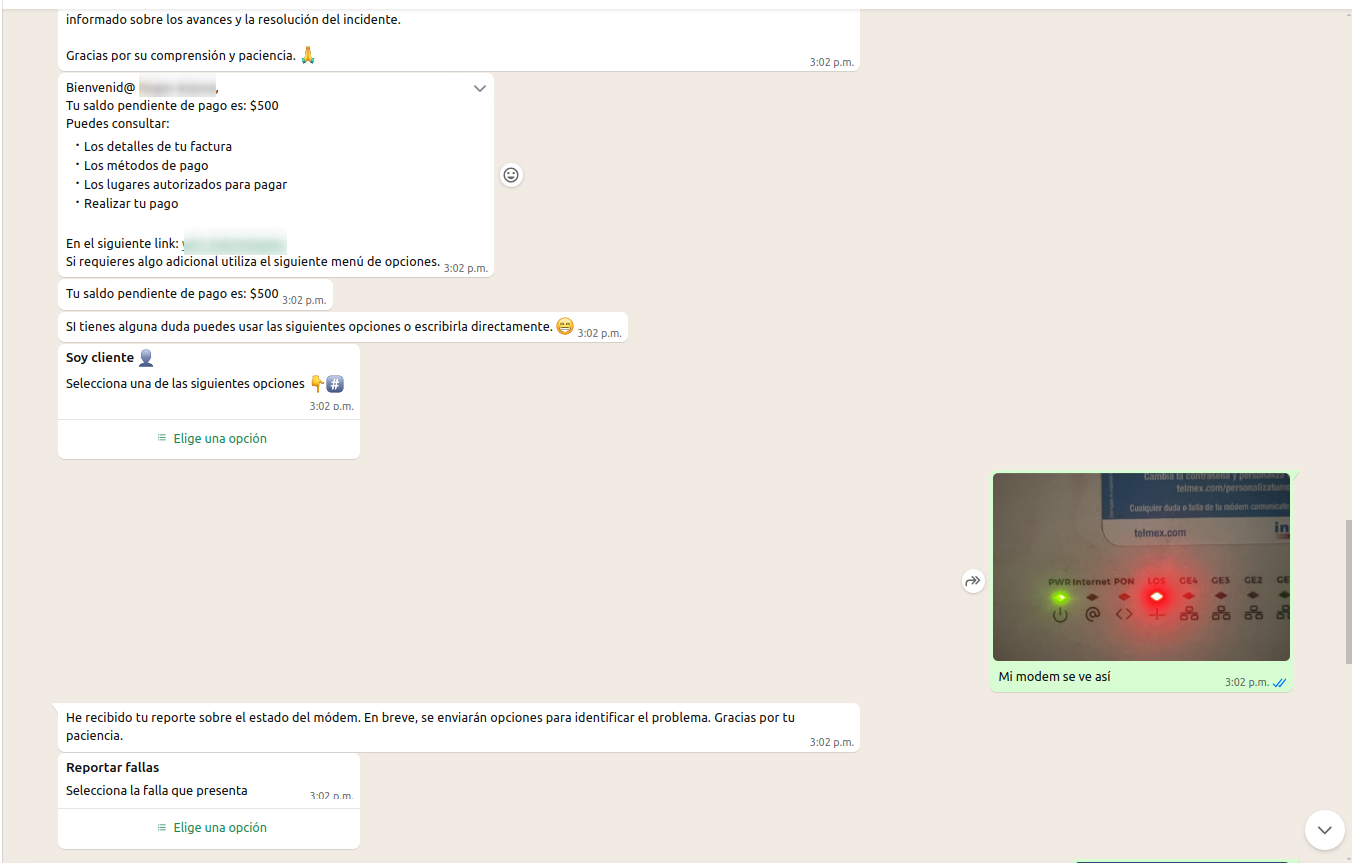
Built AI functionalities inside the CRM for support and sales teams. Developed agents that execute tools (tool/function-calling) and use RAG to respond with context from the internal knowledge base, reducing response times and improving support quality at scale.
What I Built
- Agentic workflows with PydanticAI + tool/function-calling
- RAG pipeline with internal knowledge base (pgvector + PostgreSQL)
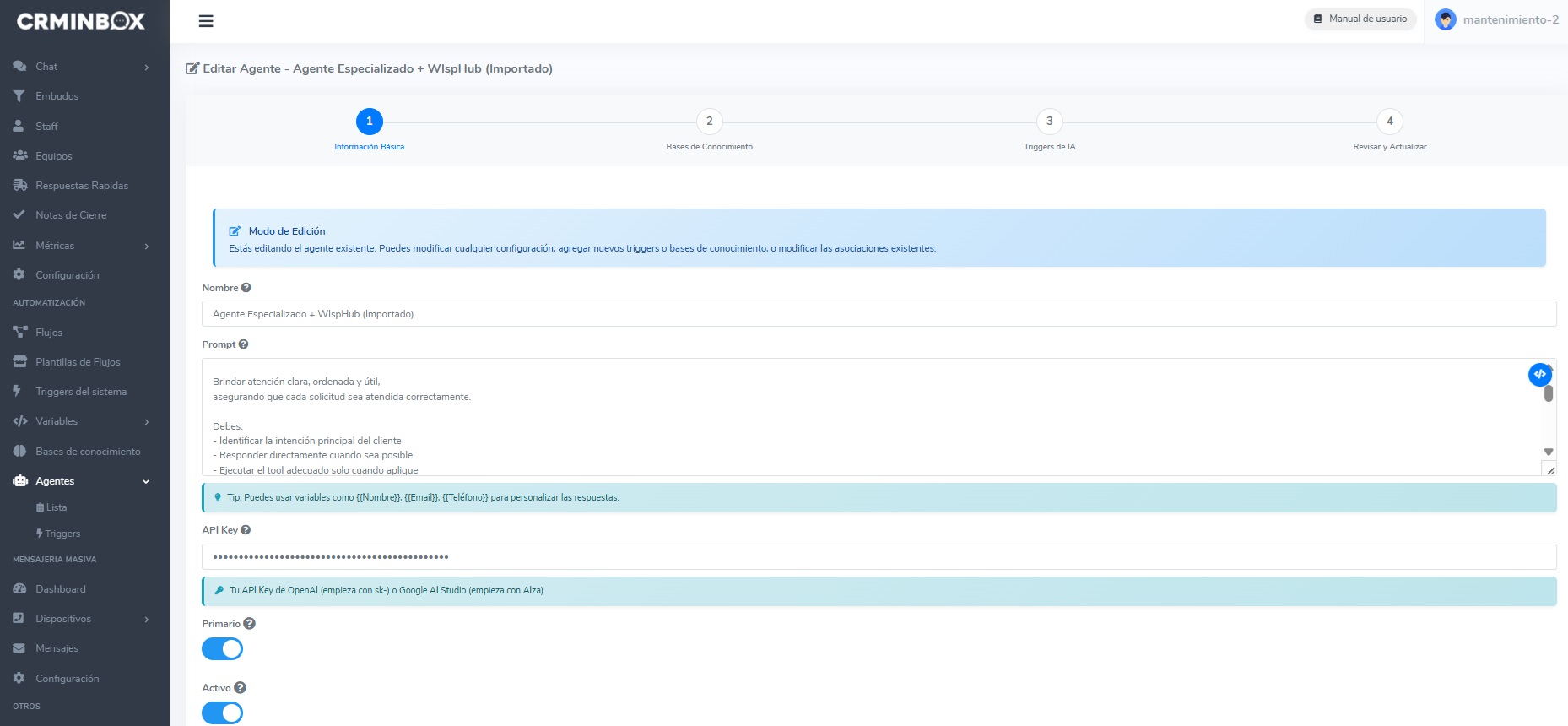
- Self-serve flow builder to configure agents without code
- Sales agents to automate first response and lead prioritization
How I Did It
- Python + Django / FastAPI + Pydantic
- OpenAI / Gemini (embeddings and completions)
- Postgres/pgvector as vector store
- Linux (DigitalOcean) + Supervisor for deployment
- Structured output validation

How we measured impact
Post-interaction satisfaction surveys, first-response times logged in the CRM, and flow adoption rate per company (internal platform data).
Cost considerations
~$5 USD per 2,000 messages estimated considering embedding + completion tokens (OpenAI/Gemini). Enables defining customer tiers and pricing decisions.
Deployment
Infrastructure on DigitalOcean (Linux), process management with Supervisor to keep workers active, Docker to isolate services and enable zero-downtime updates.
Screenshots shown with anonymized or illustrative data.
Database Assistant (Intern)
- Implemented ETL processes to clean and update the licensing database using DynamoDB in AWS
- Automated data cleaning and report generation tasks
Marketing Developer (Intern)
- Designed and fully developed application to search for potential client information
- Enabled retrieving client data for sales in seconds
Marketing Developer (Intern)
- Developed application using web scraping techniques to extract hotel information
- Facilitated data storage and analysis in CSV and Excel formats
Education
Universidad del Caribe
Final Grade: 9.23/10
Top GPA in the program
Colegio Boston Tikal
Final Grade: 9/10
Projects
WebScraperHotels
- Reduced data collection from 2 hours to less than 5 minutes
Plankton Image Dataset Creation
Complementary project to the Plankton Classifier. Collected ~600,000 images in 40 minutes from IFCB Dashboard and PlanktonNet, organized by class to enrich the original WHOI dataset (2006-2014).
Skills
AI/GenAI
Backend
Data
Infra
- ETL/ELT Pipeline Design and Implementation
- Collaboration with Cross-Functional Teams
- Data Cleaning and Preprocessing
- Data Visualization
- Performance Optimization in Big Data Environments
Certifications and Courses
Amazon Educate Badges




- Cambridge English Entry Level Certificate Level B1, Cambridge - 2016
- Oracle Next Education F2 T5 Back-end, Oracle - April 2023 - October 2023
- Operación Aleph: Microsoft Azure SC-900, Red por la ciberseguridad - 2024
- Aspectos básicos de Azure AI (IA-900), Red por la ciberseguridad - 2024
- Inteligencia Artificial en el trabajo, Red por la ciberseguridad - 2024